Table of Contents
OpenWebUI + Ollama
모델의 종류보다는 CPU/GPU 차이, GPU 종류의 차이로 성능이 결정되는 듯 하다.
물론 최소 1B 이상은 되어야 하고…
ollama 설치
curl -fsSL https://ollama.com/install.sh | sh기타 설정 변경
sudo vi /etc/systemd/system/ollama.service
-------------
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
# 외부 연결 가능하도록 설정
Environment="OLLAMA_HOST=0.0.0.0"
# 모델 파일 경로
Environment="OLLAMA_MODELS=/data/ollama/models"
# 모델 메모리에 유지
OLLAMA_KEEP_ALIIVE=-1
[Install]
WantedBy=default.target
-------------
sudo mkdir -p /data/ollama/models
sudo chown -R ollama:ollama /data/
# 서비스 활성화
sudo systemctl daemon-reload
sudo systemctl enable ollama
# 서비스 구동
sudo systemctl restart ollama
sudo systemctl status ollamaOpen WebUI 설치
mkdir open-webui
# CPU
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
# GPU
# docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda모델 불러오기
허깅 페이스에 있는 모델을 다운받아 자신만의 모델파일을 만들고 모델을 생성할 수 있습니다.
# 다운로드
wget https://huggingface.co/bartowski/llama-3.2-Korean-Bllossom-3B-GGUF/resolve/main/llama-3.2-Korean-Bllossom-3B-Q5_K_L.gguf
vi Modelfile
-------------------
FROM llama-3.2-Korean-Bllossom-3B-Q5_K_L.gguf
SYSTEM """당신은 유용한 AI 어시스턴트입니다. 사용자의 질의에 대해 친절하고 정확하게 답변해야 합니다. You are a helpful AI assistant, you'll need to answer users' queries in a friendly and accurate manner. 모든 대답은 한국어(Korean)으로 대답해주세요."""
TEMPLATE """{{- if .System }}
<s>{{ .System }}</s>
{{- end }}
<s>Human:
{{ .Prompt }}</s>
<s>Assistant:
"""
PARAMETER temperature 0.6
PARAMETER num_predict 3000
PARAMETER num_ctx 4096
PARAMETER stop <s>
PARAMETER stop </s>
PARAMETER stop <|eot_id|>
-------------------
ollama create llama-3.2-Korean-Bllossom-3B-Q5_K_L-GGUF -f ./Modelfile허깅페이스에서 제공중인 모델에 hf.co 을 붙여 그대로 설치가 가능합니다.
(GGUF 포멧인 경우)
# ollama pull hf.co/QuantFactory/llama-3.2-Korean-Bllossom-3B-GGUF
ollama list
NAME ID SIZE MODIFIED
llama-3.2-Korean-Bllossom-3B-Q5_K_L-GGUF:latest 073041344f01 2.4 GB 47 hours agoqwen2.5-coder:14b-instruct-q4_K_M
ollama 에서 제공중인 모델도 당연히 설치 가능합니다.
ollama pull qwen2.5-coder:14b-instruct-q4_K_M실행
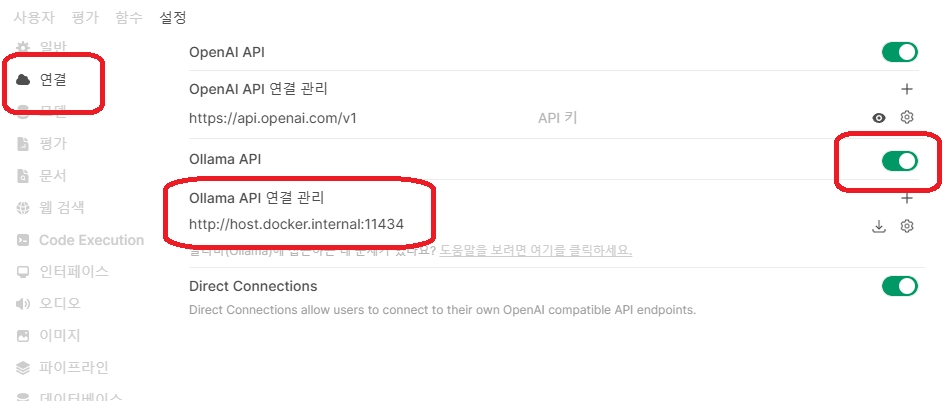
Open WebUI에 접속 (기본 URL: http://localhost:3000)
오류 대응
현상
# 호스트
curl http://localhost:11434
Ollama is running
# 컨테이너
docker exec -it open-webui /bin/bash
curl http://host.docker.internal:11434
curl: (7) Failed to connect to host.docker.internal port 11434 after 4 ms: Couldn't connect to server원인
아이피가 불일치하고 있다.
# 호스트
ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.31.94.137 netmask 255.255.240.0 broadcast 172.31.95.255
......
# 컨테이너
docker exec -it open-webui /bin/bash
curl http://host.docker.internal:11434
curl: (7) Failed to connect to host.docker.internal port 11434 after 4 ms: Couldn't connect to server
curl http://172.31.94.137:11434
Ollama is running
cat /etc/hosts
127.0.0.1 localhost
......
192.168.65.254 host.docker.internal해결책
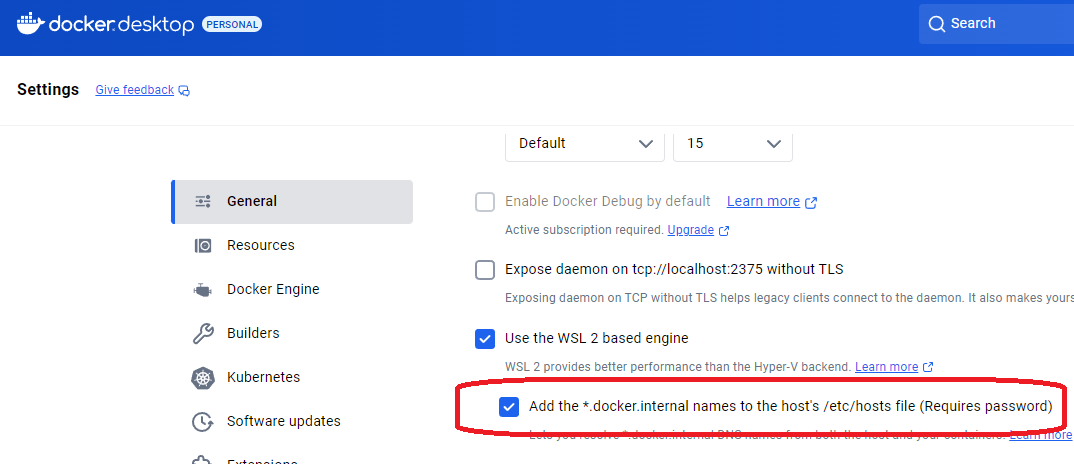
방법1: 도커 데스크탑 설정
도커 데스크탑에 아래 설정을 해준다.
아이피가 바뀌었을 때 도커 데스크탑을 재시작해야 한다.
방법2: 호스트 아이피 전달
호스트의 아이피를 넘겨주면 된다.
HOST=$(ip addr show eth0 | grep 'inet\b' | awk '{print $2}' | cut -d/ -f1)
docker run -d -p 3000:8080 --gpus all \
--add-host="host.docker.internal:$HOST" \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always ghcr.io/open-webui/open-webui:cuda방법3: hosts 파일 수정
아래 방법은 컨테이너를 재시작하면 다시 에러가 난다.
(하지만 이 방법이 가장 확실하다…)
# 컨테이너
docker exec -it open-webui /bin/bash
cp /etc/hosts ~/hosts.new
sed -i 's/192.168.65.254/172.31.94.137/g' ~/hosts.new
cp -f ~/hosts.new /etc/hosts
curl http://host.docker.internal:11434
Ollama is running버전업
docker ps
docker stop open-webui
docker rm open-webui
# CPU
docker pull ghcr.io/open-webui/open-webui:main
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
# GPU
# docker pull ghcr.io/open-webui/open-webui:cuda
# docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda